 Hallucina-Gen
Hallucina-Gen
Catch hallucinations before your users do. Get test cases that expose where your model is most likely to fail — no LLM connection required.
How It Works
If your LLM setup has it reading or extracting information from documents, it might be introducing hallucinations. Use our tool to find out.
Upload your PDFs, tell us what LLM and prompts you're using, and we'll analyze your documents to generate inputs likely to trigger hallucinations. You get a spreadsheet of risky examples to use in prompt testing, evals, and guardrails.
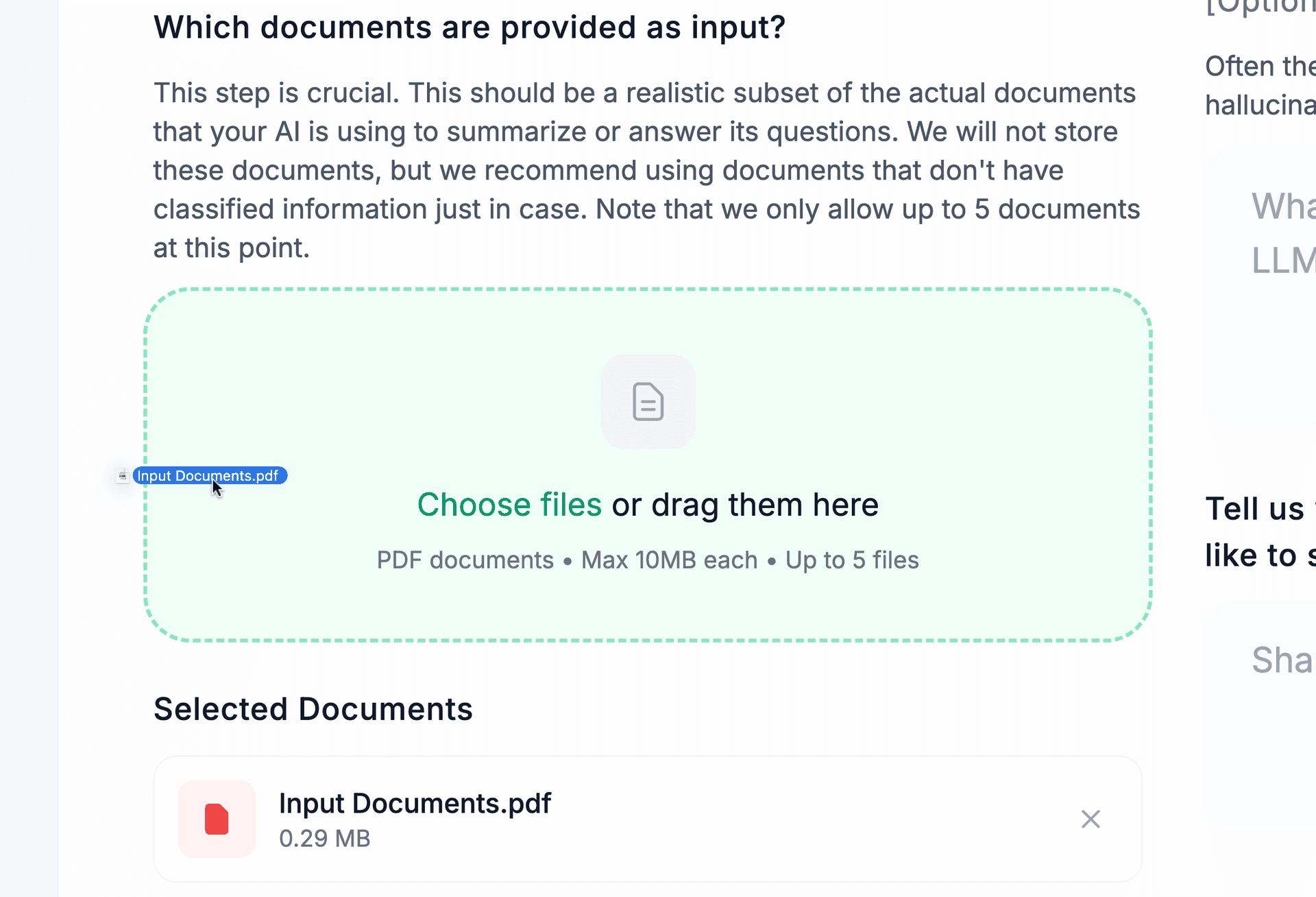
1. Upload Your Documents
Simply upload some of the PDFs your LLM will read from.
2. AI Analysis
Our advanced AI models analyze your documents to identify potential weak spots where hallucinations might occur, generating comprehensive test scenarios.

3. Receive Your Report
We generate a spreadsheet of inputs that may generate hallucinations in your LLM. Simply feed them to your LLM and check if they gave the correct response. If they did not, now you know where to improve your setup. Or, if none of the generated inputs cause your LLM to hallucinate, you can be confident you've created a robust system!

See It In Action
Watch how our tool identifies potential hallucination triggers in real-time
Who It's For
Anyone using AI to summarize or answer questions about documents — especially in high-stakes or information-dense domains — can benefit from proactively identifying where their LLM is most likely to fail.
Policy Chatbot Teams
Building chatbots that answer questions from HR manuals or compliance policies. Ensure your bot doesn't confidently give wrong answers about eligibility, process steps, or regulatory guidance.
Legal AI Developers
Working on tools that summarize or extract insights from contracts or case law PDFs. Catch places where your LLM might misinterpret clauses or invent precedents.
Internal Knowledge Tool Builders
Built Q&A interfaces over internal documentation — onboarding guides, SOPs, engineering specs — and need to validate trustworthy responses under real use.
AI Research Teams
Evaluating prompt quality and robustness over technical documents or datasets. Want a concrete, repeatable way to surface and study hallucination-prone inputs.
Enterprise RAG Developers
Deploying retrieval-augmented generation over large corpus of PDFs. Want to stress-test your setup before putting it in front of users.
And More...
This is not an exhaustive list — if you're working with LLMs and documents, chances are we can help.
What You Get
A spreadsheet of test inputs likely to trigger model hallucinations
Insight into weak spots in your prompt setup
A faster way to iterate and debug without guessing
Pricing
We keep it simple: a $4.99 flat fee for each full report. But you can generate a report and we'll give you a preview for free.